Project
A* (GPU VS CPU)
Focuses on the implementation and performance comparison of the A* pathfinding algorithm in both a sequential CPU-based version and a parallel GPU-based version using CUDA.
The main objective is to evaluate how parallelization can improve execution time and scalability when computing shortest paths on large two-dimensional graphs, while preserving the correctness and optimality guarantees of the original algorithm.
The environment is modeled as a grid-based graph in which each node represents a position in a two-dimensional space and edges connect adjacent nodes with randomly generated weights. On the CPU side, the graph is represented using pointer-based node and edge structures, while on the GPU side the same graph is converted into a compact, linear memory layout optimized for device access. This dual representation highlights the architectural differences between host and device and the need to adapt data structures to the constraints of parallel hardware.
The sequential CPU implementation follows the classic A* approach, using a priority queue implemented as a min-heap to manage the open list, alongside a closed list to track visited nodes. The algorithm iteratively expands nodes with the lowest estimated cost until the target is reached or no valid path exists. This version serves as a correctness baseline and a reference point for performance comparison.
The GPU implementation introduces a redesigned version of A* tailored for massively parallel execution. Instead of relying on a single global open list, the algorithm employs multiple parallel priority queues, one per thread, significantly reducing contention and synchronization overhead. Global cost arrays are shared across threads and updated using atomic operations to ensure correctness in concurrent updates. Hashing tables are used to prevent duplicate node insertions, while atomic compare-and-swap operations guarantee consistency when multiple threads attempt to process the same node.
A key aspect of the project is the dynamic balancing of parallel workload. The number of parallel queues is determined by a tunable parameter that directly affects how work is distributed across GPU threads. Extensive benchmarking is performed to analyze how this parameter impacts synchronization costs, parallel efficiency, and overall performance. The project demonstrates how selecting an appropriate balance between parallelism and overhead is essential to achieving optimal speedup.
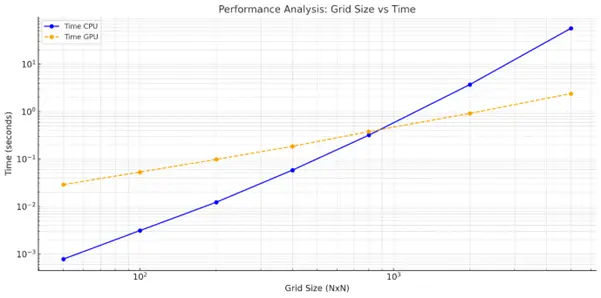
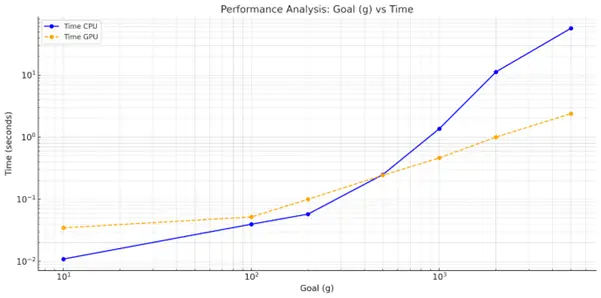
Performance evaluation is carried out on large grids, reaching sizes up to 5000×5000 nodes. The results show that while the GPU implementation may be slower for small graphs or short distances, it significantly outperforms the sequential version as problem size increases. In the largest test cases, the parallel A* algorithm achieves speedups of over twenty times compared to the CPU implementation. Additional experiments confirm that different heuristic functions have minimal impact on performance in the parallel version, while the number of explored nodes plays a critical role in determining execution time.

Use arrows to browse media